Un recorrido visual por las mayores innovaciones en Deep Learning y Computer Vision.
Antes de las CNN, la forma estándar de entrenar una red neuronal para clasificar imágenes era aplanarla en una lista de píxeles y alimentarla a una red neuronal de retroalimentación para generar la clase de la imagen. El problema del aplanamiento de imágenes es que se ignora la información espacial esencial de la imagen.
En 1989, Yann LeCun y su equipo introdujeron las redes neuronales convolucionales, pilares de la investigación en visión por computadora durante 15 años. A diferencia de las redes de propagación directa, las CNN preservan la naturaleza 2D de las imágenes y son capaces de procesar información espacialmente.
En este artículo, recorreremos la historia de las CNN específicamente para tareas de clasificación de imágenes, desde esos primeros años de investigación en la década de 1990 hasta la edad de oro de mediados de la década de 2010, cuando se diseñaron muchas de las mejores arquitecturas de aprendizaje profundo jamás diseñadas. Se han diseñado y, finalmente, se analizan las últimas tendencias de investigación en las CNN actuales, ya que compiten con los transformadores de atención y visión.
Controlar video de Youtube que explica todos los conceptos de este artículo de forma visual con animaciones. A menos que se indique lo contrario, todas las imágenes e ilustraciones utilizadas en este artículo las genero yo mismo durante la creación de la versión en video.

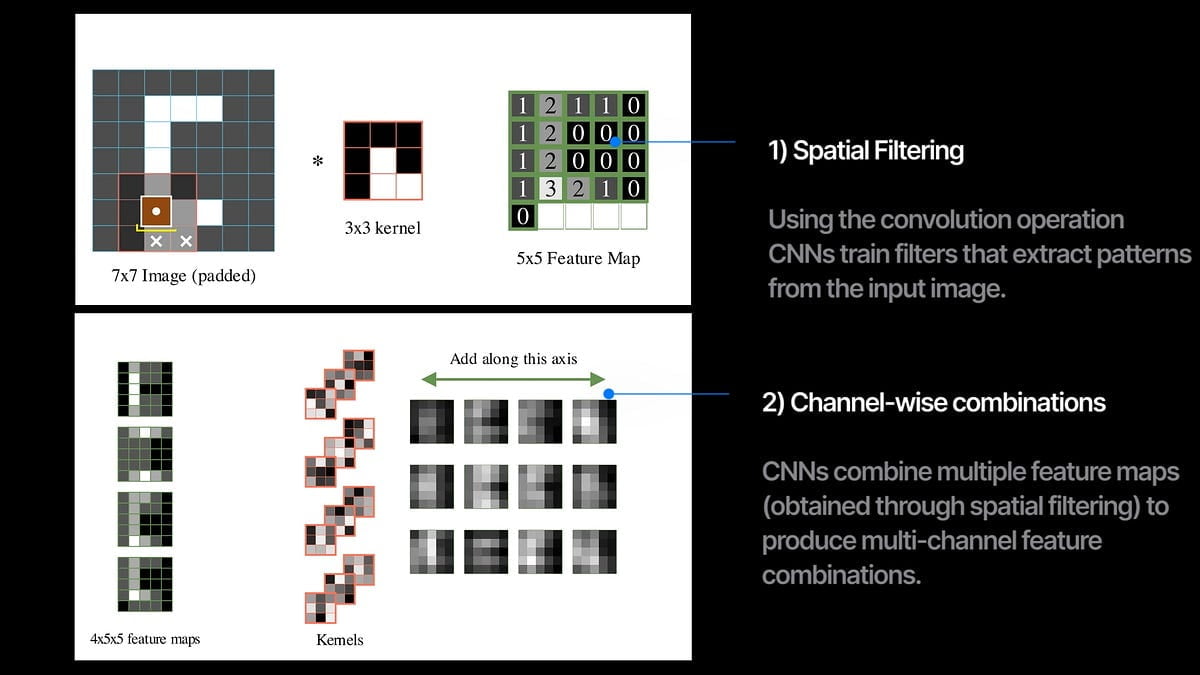
En el corazón de una CNN está la operación de convolución. Analizamos el filtro en la imagen y calculamos el producto escalar del filtro con la imagen en cada ubicación de superposición. El resultado resultante se denomina mapa de características y captura cuánto y dónde está presente el patrón de filtro en la imagen.

En una capa convolucional, entrenamos múltiples filtros que extraen diferentes mapas de características de la imagen de entrada. Cuando apilamos varias capas convolucionales en secuencia con cierta no linealidad, obtenemos una red neuronal convolucional (CNN).
Entonces, cada capa de convolución hace dos cosas simultáneamente:
1. filtrado espacial con la operación de convolución entre imágenes y núcleos, y
2. combinando múltiples canales de entrada y genera un nuevo conjunto de canales.
El 90% de la investigación de CNN se ha centrado en cambiar o mejorar sólo estos dos elementos.

El documento de 1989
Este documento de 1989 nos enseñó cómo entrenar CNN no lineales desde cero mediante retropropagación. Introducen imágenes en escala de grises de 16×16 de dígitos escritos a mano y pasan a través de dos capas convolucionales con 12 filtros de tamaño 5×5. Los filtros también se mueven en pasos de 2 durante el escaneo. La convolución escalonada es útil para reducir la resolución de la imagen de entrada. Después de las capas de convolución, los mapas de salida se aplanan y pasan a través de dos redes completamente conectadas para generar las probabilidades de los 10 dígitos. Utilizando la pérdida de entropía cruzada de softmax, la red se optimiza para predecir etiquetas correctas para dígitos escritos a mano. Después de cada capa, también se utiliza la no linealidad tanh, lo que permite que los mapas de características aprendidos sean más complejos y expresivos. Con sólo 9760 parámetros, se trataba de una red muy pequeña en comparación con las redes actuales que contienen cientos de millones de parámetros.

Sesgo inductivo
El sesgo inductivo es un concepto de aprendizaje automático en el que introducimos deliberadamente reglas y limitaciones específicas en el proceso de aprendizaje para alejar nuestros modelos de las generalizaciones y acercarlos más a soluciones que sigan nuestra comprensión humana.
Cuando los humanos clasificamos imágenes, también realizamos filtrado espacial buscar patrones comunes para formar múltiples representaciones y luego combinarlos para formar nuestras predicciones. La arquitectura de CNN está diseñada para replicar exactamente esto. En las redes de retroalimentación, cada píxel se trata como su propia característica aislada, porque cada neurona en las capas se conecta a todos los píxeles. En las CNN, se comparten más parámetros porque el mismo filtro analiza la imagen completa. Los sesgos inductivos también hacen que las CNN requieran menos datos porque obtienen el reconocimiento de patrones locales de forma gratuita desde el diseño de la red, pero las redes de avance deben dedicar sus ciclos de capacitación a aprender sobre ello desde cero.