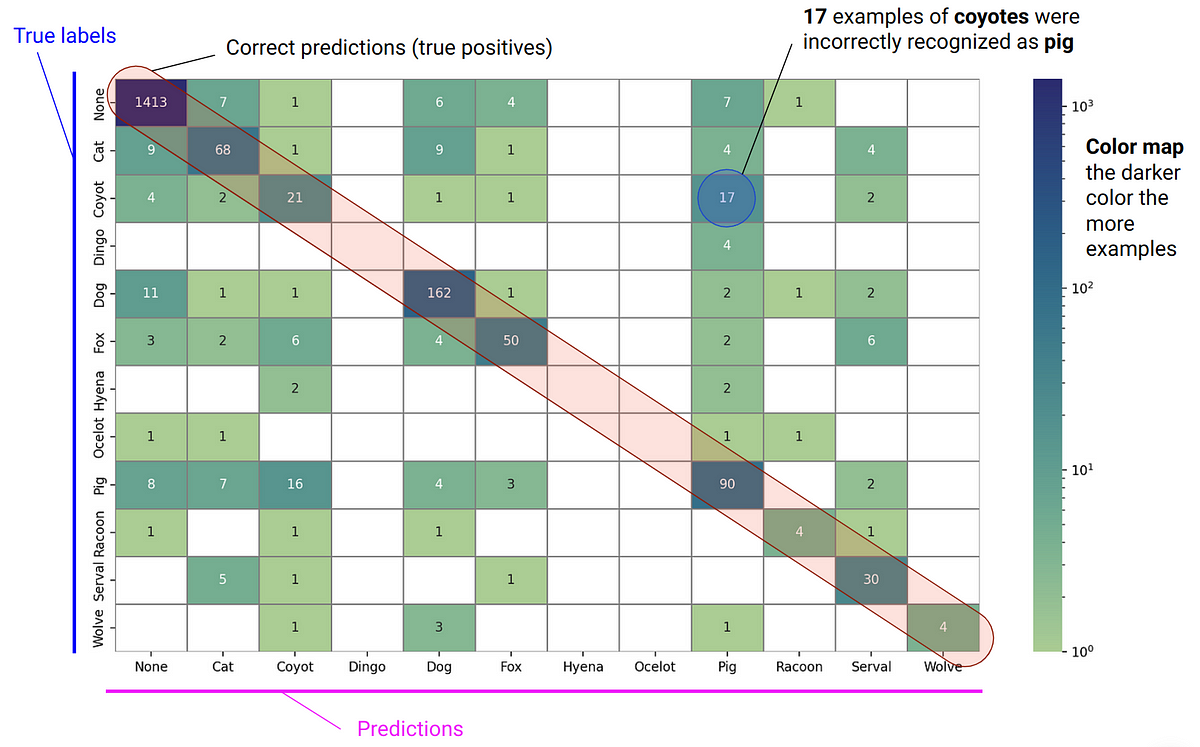
El excelente desempeño de modelos de lenguajes grandes (LLM) como ChatGPT ha conmocionado al mundo. El gran avance se logró con la invención de la arquitectura Transformer, que es sorprendentemente simple y escalable. Todavía se basa en redes neuronales de aprendizaje profundo. La principal incorporación es el llamado mecanismo de “atención” que contextualiza cada token de palabra. Además, sus paralelismos sin precedentes brindan a los LLM una escalabilidad masiva y, por lo tanto, una precisión impresionante después del entrenamiento en miles de millones de parámetros.
La simplicidad demostrada por la arquitectura Transformer es de hecho comparable a la de la máquina de Turing. La diferencia es que la máquina de Turing controla lo que puede hacer en cada paso. El Transformer, por otro lado, es como una caja negra mágica, que aprende de datos de entrada masivos mediante optimizaciones de parámetros. Los investigadores y científicos siguen muy interesados en descubrir su potencial y posibles implicaciones teóricas para el estudio de la mente humana.
En este artículo, primero discutiremos las cuatro características principales de la arquitectura Transformer: incrustación de palabras, mecanismo de atención, predicción de una sola palabra y capacidades de generalización, como la expansión multimodal y el aprendizaje transferido. La intención es centrarse en por qué la arquitectura es tan efectiva en lugar de cómo construirla (para lo cual los lectores pueden encontrar mucha información sobre cómo construirla).