Las series de tiempo y especialmente la previsión de series de tiempo son un problema de ciencia de datos muy conocido entre los profesionales y usuarios empresariales.
Existen varios métodos de pronóstico, que se pueden agrupar en métodos estadísticos o de aprendizaje automático para una mejor comprensión y visión general, pero, de hecho, la demanda de pronóstico es tan alta que las opciones disponibles son abundantes.
Los métodos de aprendizaje automático se consideran un enfoque de vanguardia en el pronóstico de series temporales y están ganando popularidad debido al hecho de que son capaces de capturar relaciones complejas no lineales dentro de los datos y, en general, producen una mayor precisión en los pronósticos. [1]. Un área popular del aprendizaje automático es el panorama de las redes neuronales. Específicamente para el análisis de series temporales, se han desarrollado y aplicado redes neuronales recurrentes para resolver problemas de predicción. [2].
Los entusiastas de la ciencia de datos pueden encontrar intimidante la complejidad detrás de estos modelos y, siendo uno de ustedes, puedo decir que comparto ese sentimiento. Sin embargo, este artículo pretende mostrar que
A pesar de los últimos avances en métodos de aprendizaje automático, no necesariamente vale la pena lanzarse a la aplicación más compleja cuando se busca una solución a un problema en particular. Los métodos bien establecidos, mejorados por poderosas técnicas de ingeniería de características, aún podrían proporcionar resultados satisfactorios.
Específicamente, aplico un modelo de Perceptrón multicapa y comparto el código y los resultados, para que usted pueda obtener experiencia práctica en ingeniería de características de series temporales y pronósticos efectivos.
Más concretamente, lo que quiero aportar a los profesionales autodidactas se podría resumir en los siguientes puntos:
- predicciones basadas en problemas/datos del mundo real
- cómo diseñar características de series de tiempo para capturar patrones temporales
- construir un modelo MLP capaz de usar variables mixtas: flotantes y enteros (tratados como variables categóricas mediante integración)
- utilizar MLP para la predicción de puntos
- utilice MLP para realizar pronósticos de varios pasos
- evaluar la importancia de las características utilizando el método de permutación de la importancia de las características
- volver a entrenar el modelo para un subconjunto de características agrupadas (múltiples grupos, entrenados para grupos individuales) para refinar la importancia de las características agrupadas
- evaluar el modelo comparándolo con un
UnobservedComponentsmodelo
Tenga en cuenta que este artículo supone un conocimiento previo de algunos términos técnicos clave y no pretende explicarlos en detalle. Encuentre estos términos clave a continuación, con referencias proporcionadas, que se pueden verificar para mayor claridad:
- Series de tiempo [3]
- Predicción [4] — en este contexto, se utilizará para distinguir los resultados del modelo durante el período de formación
- Pronóstico [4] — en este contexto, se utilizará para distinguir los resultados del modelo durante el período de prueba
- Ingeniería de características [5]
- Autocorrelación [6]
- Autocorrelación parcial [6]
- MLP (perceptrón multicapa) [7]
- Capa de entrada [7]
- capa oculta [7]
- Capa de salida [7]
- Incorporación [8]
- Modelos de espacio de estados [9]
- Modelo de componentes no observados [9]
- RMSE (error cuadrático medio) [10]
- Importancia de las características [11]
- Importancia de la función de permutación [11]
Los paquetes esenciales utilizados durante el análisis son numpy Y pandas para la manipulación de datos, plotly para gráficos interactivos, statsmodels para estadísticas y modelado del espacio de estados y, finalmente, tensorflow para la arquitectura MLP.
Nota: Debido a limitaciones técnicas, proporcionaré fragmentos de código para el trazado interactivo, pero las figuras se presentarán aquí de forma estática.
import opendatasets as od
import numpy as np
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import tensorflow as tffrom sklearn.preprocessing import StandardScaler
from sklearn.inspection import permutation_importance
import statsmodels.api as sm
from statsmodels.tsa.stattools import acf, pacf
import datetime
import warnings
warnings.filterwarnings('ignore')
Los datos se cargan automáticamente usando opendatasets.
dataset_url = "https://www.kaggle.com/datasets/robikscube/hourly-energy-consumption/"
od.download(dataset_url)
df = pd.read_csv(".\hourly-energy-consumption" + "\AEP_hourly.csv", index_col=0)
df.sort_index(inplace = True)
Tenga en cuenta que limpiar los datos fue un primer paso esencial para avanzar con el análisis. Si está interesado en detalles y también en el modelado del espacio de estados, consulte mi artículo anterior. aquí. ☚📰 En resumen se realizaron los siguientes pasos:
- Identificación de lagunas, cuando faltan marcas de tiempo específicas (solo se han identificado pasos individuales)
- Realizar imputación (usando el promedio de registros anteriores y siguientes)
- Identificar y eliminar duplicados
- Establecer la columna de marca de tiempo como índice para el marco de datos
- Establezca la frecuencia de índice del marco de datos en cada hora, ya que este es un requisito para el procesamiento posterior.
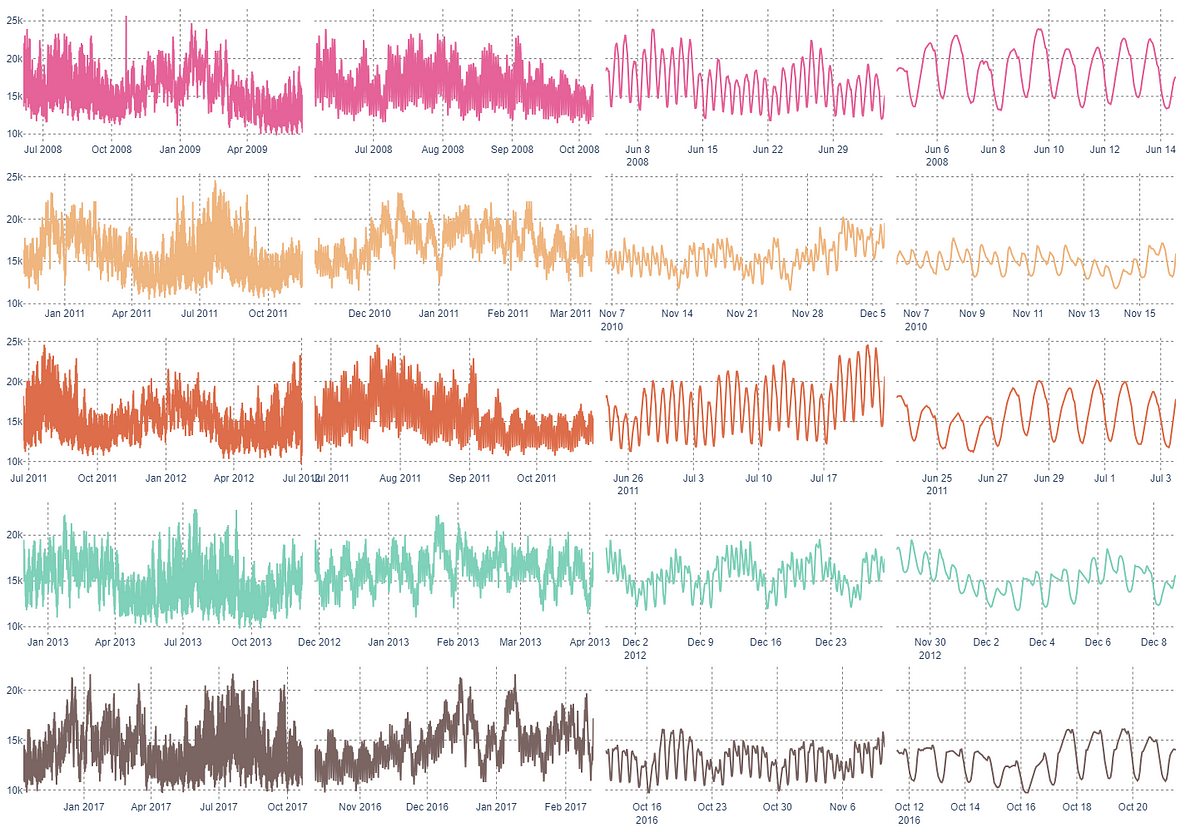
Después de preparar los datos, exploremos extrayendo 5 muestras de marcas de tiempo aleatorias y comparemos las series de tiempo en diferentes escalas.
fig = make_subplots(rows=5, cols=4, shared_yaxes=True, horizontal_spacing=0.01, vertical_spacing=0.04)# drawing a random sample of 5 indices without repetition
sample = sorted([x for x in np.random.choice(range(0, len(df), 1), 5, replace=False)])
# zoom x scales for plotting
periods = [9000, 3000, 720, 240]
colors = ["#E56399", "#F0B67F", "#DE6E4B", "#7FD1B9", "#7A6563"]
# s for sample datetime start
for si, s in enumerate(sample):
# p for period length
for pi, p in enumerate(periods):
cdf = df.iloc[s:(s+p+1),:].copy()
fig.add_trace(go.Scatter(x=cdf.index,
y=cdf.AEP_MW.values,
marker=dict(color=colors[si])),
row=si+1, col=pi+1)
fig.update_layout(
font=dict(family="Arial"),
margin=dict(b=8, l=8, r=8, t=8),
showlegend=False,
height=1000,
paper_bgcolor="#FFFFFF",
plot_bgcolor="#FFFFFF")
fig.update_xaxes(griddash="dot", gridcolor="#808080")
fig.update_yaxes(griddash="dot", gridcolor="#808080")