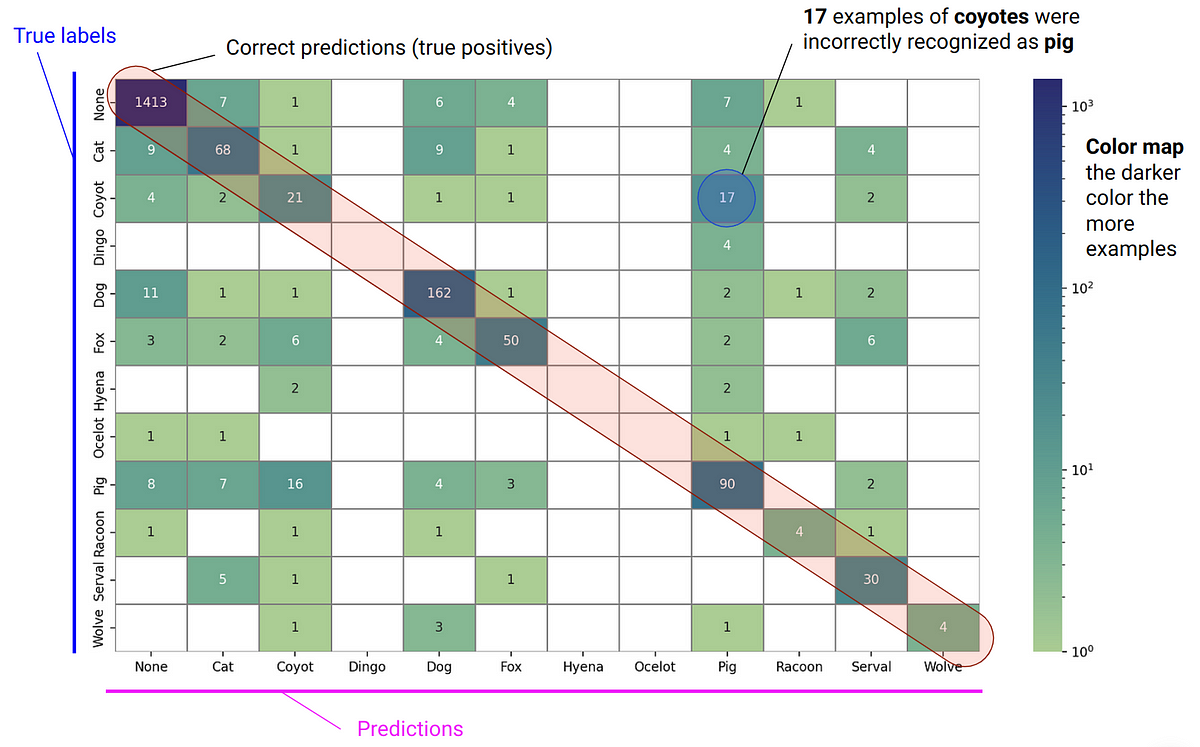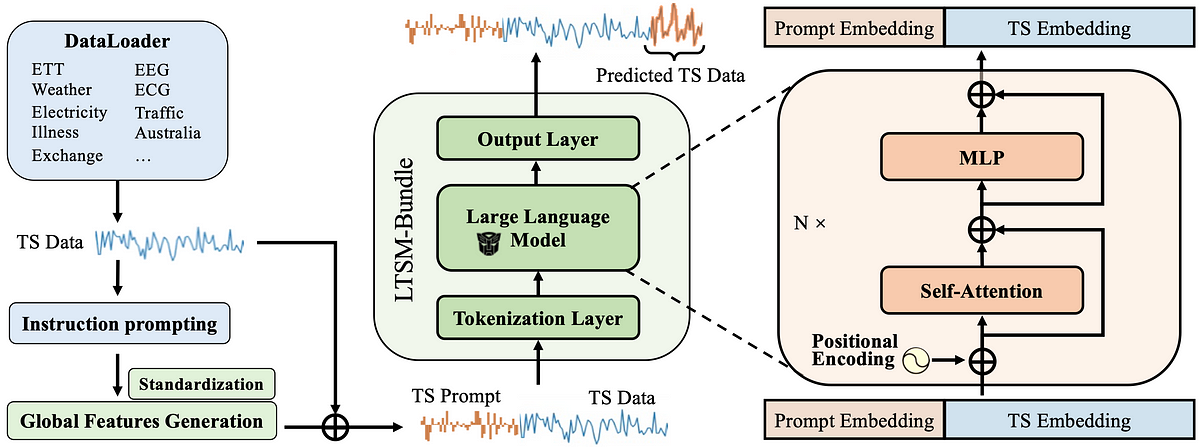
6. La combinación de todos estos crea un modelo LTSM (LTSM-Bundle) que supera a todos los métodos existentes que reprograman LLM para series de tiempo y modelos de pronóstico de series de tiempo basados en transformadores.

¡Reprograme usted mismo un LTSM!
¿Quieres intentar reprogramar tu propio LTSM? Aquí está el tutorial para el paquete LTSM: https://github.com/daochenzha/ltsm/blob/main/tutorial/README.md
Paso 1: crea un entorno virtual. Clona e instala los requisitos y el repositorio.
conda create -n ltsm python=3.8.0
conda activate ltsm
git clone git@github.com:daochenzha/ltsm.git
cd ltsm
pip3 install -e .
pip3 install -r requirements.txt
Paso 2: prepare su conjunto de datos. Asegúrese de que su carpeta de datos local se vea como la siguiente:
- ltsm/
- datasets/
DATA_1.csv/
DATA_2.csv/
DATA_3.csv/
...
Paso 3: Generar indicaciones de series temporales a partir de los conjuntos de datos de entrenamiento, validación y prueba.
python3 prompt_generate_split.py
Paso 4: busque las indicaciones de series temporales generadas en la carpeta “./prompt_data_split”. Luego ejecute el siguiente comando para finalizar las indicaciones:
# normalizing the prompts
python3 prompt_normalization_split.py --mode fit#export the prompts to the "./prompt_data_normalize_split" folder
python3 prompt_normalization_split.py --mode transform
Paso final: entrene su propio LTSM con Time Series Prompt y Linear Tokenization en gpt2-medium.
python3 main_ltsm.py \
--model LTSM \
--model_name_or_path gpt2-medium \
--train_epochs 500 \
--batch_size 10 \
--pred_len 96 \
--data_path "DATA_1.csv DATA_2.csv" \
--test_data_path_list "DATA_3.csv" \
--prompt_data_path "prompt_bank/prompt_data_normalize_split" \
--freeze 0 \
--learning_rate 1e-3 \
--downsample_rate 20 \
--output_dir [Your_Output_Path] \
Descubra más detalles en nuestro artículo y en nuestro repositorio de GitHub:
Papel: https://arxiv.org/pdf/2406.14045
Codificado: https://github.com/daochenzha/ltsm/
Referencia:
[1] Liu, Pengfei et al. «Preentrenar, incitar y predecir: un estudio sistemático de los métodos de incitación en el procesamiento del lenguaje natural». » Investigaciones informáticas de ACM 55,9 (2023): 1–35.
[2] Liu, Xiao y cols. “Aprendizaje autodirigido: generativo o contrastivo. » Transacciones IEEE sobre conocimiento e ingeniería de datos 35.1 (2021): 857–876.
[3] Ansari, Abdul Fatir y otros. “Chronos: aprendiendo el lenguaje de las series temporales. » arXiv preimpresión arXiv:2403.07815 (2024).