

Investigadores de DeepMind de Google han presentado un nuevo método para acelerar el entrenamiento de IA, reduciendo significativamente los recursos informáticos y el tiempo necesario para realizar el trabajo. Según un estudio reciente, este nuevo enfoque del proceso que normalmente consume mucha energía podría hacer que el desarrollo de la IA sea más rápido y más barato. trabajo de investigación– y eso podría ser una buena noticia para el medio ambiente.
«Nuestro enfoque, el aprendizaje contrastivo multimodal con selección conjunta de ejemplos (JEST), supera a los modelos de última generación con hasta 13 veces menos iteraciones y 10 veces menos cálculos», afirma el estudio.
El sector de la IA es conocido por su alto consumo de energía. Los sistemas de inteligencia artificial a gran escala como ChatGPT requieren una potencia de procesamiento significativa, lo que a su vez requiere mucha energía y agua para enfriar estos sistemas. Se dice que el consumo de agua de Microsoft, por ejemplo, aumentó un 34% entre 2021 y 2022 debido al aumento de las necesidades informáticas de IA, y se acusa a ChatGPT de consumir casi medio litro de agua cada 5 a 50 solicitudes.
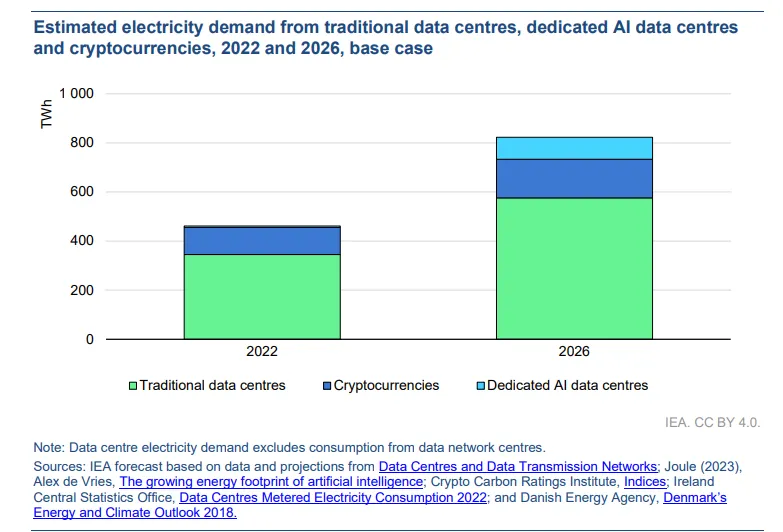
La Agencia Internacional de la Energía (AIE) proyectos que el consumo de electricidad de los centros de datos se duplicará entre 2022 y 2026, lo que genera comparaciones entre las necesidades energéticas de la IA y el perfil energético a menudo criticado de la industria minera de criptomonedas.
Sin embargo, enfoques como JEST podrían ofrecer una solución. Al optimizar la selección de datos para el entrenamiento de IA, dijo Google, JEST puede reducir significativamente la cantidad de iteraciones y la potencia informática necesaria, lo que podría disminuir el consumo general de energía. Este método es parte de los esfuerzos para mejorar la eficiencia de las tecnologías de IA y mitigar su impacto ambiental.
Si la técnica resulta eficaz a escala, los entrenadores de IA necesitarán sólo una fracción de la potencia utilizada para entrenar sus modelos. Esto significa que podrían crear herramientas de inteligencia artificial más potentes con los mismos recursos que utilizan actualmente o consumir menos recursos para desarrollar nuevos modelos.
Cómo funciona JEST
JEST funciona seleccionando lotes de datos complementarios para maximizar la capacidad de aprendizaje del modelo de IA. A diferencia de los métodos tradicionales que seleccionan ejemplos individuales, este algoritmo tiene en cuenta la composición del todo.
Imagina, por ejemplo, que estás aprendiendo varios idiomas. En lugar de aprender inglés, alemán y noruego por separado, tal vez en orden de dificultad, puede que le resulte más eficaz estudiarlos juntos para que el conocimiento de uno promueva el aprendizaje del otro.
Google adoptó un enfoque similar y resultó exitoso.
«Demostramos que seleccionar conjuntamente lotes de datos es más eficaz para el aprendizaje que seleccionar ejemplos de forma independiente», dijeron los investigadores en su artículo.
Para hacer esto, los investigadores de Google utilizaron «aprendizaje contrastivo multimodal», donde el proceso JEST identificó dependencias entre puntos de datos. Este método mejora la velocidad y la eficiencia del entrenamiento de la IA y requiere una potencia informática significativamente menor.
Según Google, la clave de este enfoque fue comenzar con modelos de referencia previamente entrenados para guiar el proceso de selección de datos. Esta técnica permitió que el modelo se centrara en conjuntos de datos bien organizados y de alta calidad, optimizando aún más la eficiencia del entrenamiento.
«La calidad de un lote también es función de su composición, además de la calidad sumada de sus puntos de datos considerados de forma independiente», explica el artículo.
Los experimentos realizados como parte del estudio mostraron mejoras significativas en el rendimiento en varios puntos de referencia. Por ejemplo, la capacitación en el conjunto de datos Common WebLI utilizando JEST mostró mejoras notables en la velocidad de aprendizaje y la eficiencia de los recursos.
Los investigadores también descubrieron que el algoritmo detectaba rápidamente sublotes altamente digeribles, acelerando el proceso de entrenamiento al centrarse en elementos de datos específicos que «coinciden» entre sí. Esta técnica, denominada «arranque de calidad de datos», prioriza la calidad sobre la cantidad y ha demostrado ser más eficaz para entrenar la IA.
“Un modelo de referencia entrenado en un pequeño conjunto de datos seleccionados puede guiar eficazmente la curación de un conjunto de datos mucho más grande, permitiendo el entrenamiento de un modelo que supera con creces la calidad del modelo de referencia en muchas tareas posteriores”, indica el documento.
Editado por Ryan Ozawa.
Generalmente inteligente Boletin informativo
Un viaje semanal de IA contado por Gen, un modelo de IA generativa.



