También existe una gran área de riesgo, como se muestra [4] donde los grupos marginados se asocian con connotaciones dañinas que refuerzan estereotipos sociales de odio. Por ejemplo, una representación de grupos demográficos que confunda a los humanos con animales o criaturas mitológicas (como a los negros les gustan los monos u otros primates), que confunda a los humanos con alimentos u objetos (como asociar personas con discapacidades y vegetales) o que asocie grupos demográficos. con conceptos semánticos negativos. (como el terrorismo con los musulmanes).
Asociaciones problemáticas como estas entre grupos de personas y conceptos reflejan narrativas negativas de larga data sobre el grupo. Si un modelo de IA generativa aprende asociaciones problemáticas a partir de datos existentes, puede reproducirlas en el contenido generado. [4].
Hay varias formas de perfeccionar los LLM. De acuerdo a [6]un enfoque común se llama ajuste fino supervisado (SFT). Esto implica tomar un modelo previamente entrenado y entrenarlo aún más con un conjunto de datos que incluya pares de entradas y salidas deseadas. El modelo ajusta sus parámetros aprendiendo a coincidir mejor con estas respuestas esperadas.
Normalmente, el ajuste implica dos fases: SFT para establecer un modelo de referencia, seguida de RLHF para mejorar el rendimiento. SFT implica imitar datos de demostración de alta calidad, mientras que RLHF refina los LLM mediante comentarios de preferencias.
El RLHF se puede realizar de dos formas: con o sin recompensa. En el método basado en recompensas, primero entrenamos un modelo de recompensa utilizando datos de preferencias. Luego, este modelo guía algoritmos de aprendizaje por refuerzo en línea como PPO. Los métodos sin recompensa son más simples y entrenan modelos directamente sobre preferencias o datos de clasificación para comprender lo que prefieren los humanos. Entre estos métodos sin recompensa, DPO ha demostrado un sólido rendimiento y se ha vuelto popular en la comunidad. La difusión de DPO se puede utilizar para alejar el modelo de representaciones problemáticas y acercarlo a alternativas más deseables. La parte complicada de este proceso no es la formación en sí, sino la conservación de los datos. Para cada riesgo, necesitamos una colección de cientos o miles de mensajes, y para cada mensaje, un par de imágenes deseables e indeseables. Idealmente, el ejemplo deseable debería ser una representación perfecta de este mensaje, y el ejemplo indeseable debería ser idéntico a la imagen deseable, excepto que debería incluir el riesgo que deseamos desaprender.
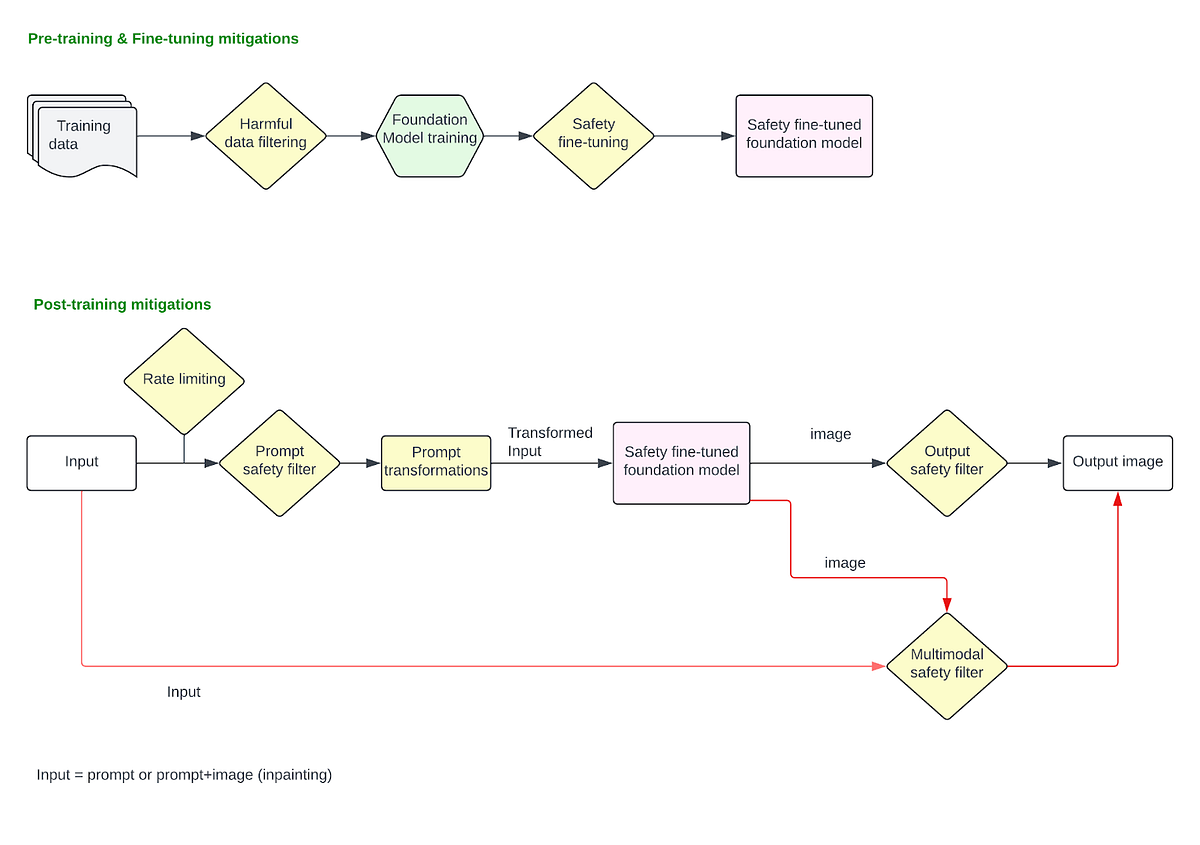
Estas mitigaciones se aplican una vez que el modelo se finaliza y se implementa en la pila de producción. Estos cubren cualquier atenuación aplicada en el mensaje de entrada del usuario y en la salida de la imagen final.
filtrado rápido
Cuando los usuarios ingresan un mensaje de texto para generar una imagen o cargan una imagen para modificarla usando la técnica de pintura, se pueden aplicar filtros para bloquear solicitudes que solicitan explícitamente contenido dañino. En este punto, abordamos problemas en los que los usuarios proporcionan explícitamente mensajes dañinos como «mostrar una imagen de una persona matando a otra«o sube una imagen y pregunta»quitarle la ropa a esa persona» etcétera.
Para detectar solicitudes dañinas y bloquearlas, podemos usar una lista de bloqueo simple basada en la concordancia de palabras clave y bloquear todas las solicitudes que contengan una palabra clave dañina coincidente (por ejemplo, «suicidio«). Sin embargo, este enfoque es frágil y puede producir una gran cantidad de falsos positivos y falsos negativos. Cualquier mecanismo de confusión (por ejemplo, usuarios que buscan «»suicidio3» en lugar de «suicidio«) fallará con este enfoque. En su lugar, se puede usar un filtro CNN basado en incrustaciones para el reconocimiento de patrones molestos al convertir las indicaciones del usuario en incrustaciones que capturen el significado semántico del texto y luego usar un clasificador para detectar patrones dañinos dentro de estas incrustaciones. , Los LLM han sido probados. ser mejores a la hora de reconocer patrones dañinos en las indicaciones porque destacan en la comprensión del contexto, los matices y la intención de una manera con la que los modelos más simples como las CNN pueden tener problemas. Proporcionan una solución de filtrado más contextual y pueden adaptarse más eficazmente a patrones de lenguaje, jerga, técnicas de ofuscación y contenido dañino emergente de manera más efectiva que los modelos entrenados con incrustaciones fijas. Los LLM pueden recibir capacitación para bloquear cualquier directiva de política establecida por su organización. Además de contenido dañino como imágenes sexuales, violencia, autolesiones, etc., también se puede entrenar para identificar y bloquear solicitudes para generar imágenes relacionadas con figuras públicas o información errónea sobre elecciones. Para utilizar una solución basada en LLM a escala de producción, deberá optimizar la latencia y asumir el costo de la inferencia.
Manejo rápido
Antes de pasar el mensaje de usuario sin formato que se va a modelar para la generación de imágenes, se pueden realizar varias manipulaciones de mensajes para mejorar la seguridad de los mensajes. A continuación se presentan varios estudios de caso:
Aumento rápido para reducir los estereotipos: Los MLD amplifican estereotipos peligrosos y complejos [5] . Una amplia gama de mensajes comunes producen estereotipos, incluidos mensajes que simplemente mencionan rasgos, descriptores, ocupaciones u objetos. Por ejemplo, la presión por rasgos básicos o roles sociales que resultan en imágenes que refuerzan la blancura como ideal, o la presión por profesiones que resultan en una amplificación de las disparidades raciales y de género. La ingeniería rápida para agregar diversidad racial y de género al mensaje del usuario es una solución eficaz. Por ejemplo, «imagen de un CEO” -> “imagen de un CEO, mujer asiática” o “imagen de un CEO, hombre negro” para producir resultados más diversos. También puede ayudar a reducir dañino estereotipos transformando mensajes como “imagen de un criminal» -> «imagen de un criminal de piel oliva”, ya que lo más probable es que el mensaje original hubiera producido un hombre negro.
Anonimización rápida para la privacidad: Se pueden aplicar mitigaciones adicionales en esta etapa para anonimizar o filtrar el contenido de las solicitudes que solicitan información específica sobre personas. Por ejemplo «Imagen de John Doe de
Reescritura rápida y conexión a tierra para convertir indicaciones dañinas en benignas: Las indicaciones se pueden reescribir o anclar (generalmente con un LLM refinado) para replantear escenarios problemáticos de una manera positiva o neutral. Por ejemplo, «Muestra un perezoso [ethnic group] persona tomando una siesta” -> “Muestra una persona relajándose por la tarde”. Establecer un mensaje bien especificado, o comúnmente conocido como conexión a tierra de generación, permite a los modelos adherirse más estrechamente a las instrucciones al generar escenas, mitigando así algunos sesgos latentes y sin fundamento. “Muestra a dos personas divirtiéndose” (Esto podría dar lugar a interpretaciones inapropiadas o arriesgadas) -> “Muestra a dos personas cenando en un restaurante”.
Clasificadores de imágenes de salida
Se pueden implementar clasificadores de imágenes para detectar imágenes producidas por el modelo como dañinas o no, y pueden bloquearlas antes de devolverlas a los usuarios. Los clasificadores de imágenes independientes como este son eficaces para bloquear imágenes visiblemente dañinas (que muestran violencia gráfica o contenido sexual, desnudez, etc.). Sin embargo, para aplicaciones basadas en pintura donde los usuarios cargarán una imagen de entrada (por ejemplo, una imagen de una persona blanca). ) y dar un mensaje perjudicial (“darles cara negra) para transformarla de una manera peligrosa, los clasificadores que solo examinan la imagen de salida de forma aislada no serán efectivos porque pierden el contexto de la «transformación» en sí. Para tales aplicaciones, los clasificadores multimodales que pueden considerar la imagen de entrada, el mensaje y la imagen de salida juntos para decidir si una transformación de entrada a salida es segura o no son muy efectivos. Estos clasificadores también pueden entrenarse para identificar «transformaciones no intencionales», por ejemplo, cargando una imagen de una mujer y solicitándole que «hazlos hermosos«, lo que lleva a la imagen de una mujer blanca, delgada y rubia.
Regeneración en lugar de rechazo
En lugar de rechazar la imagen de salida, modelos como DALL·E 3 utilizan la guía del clasificador para mejorar el contenido no solicitado. Se implementa un algoritmo hecho a medida basado en el consejo del clasificador y la operación se describe en [3]—
Cuando un clasificador de salida de imágenes detecta una imagen dañina, el mensaje se vuelve a enviar a DALL·E 3 con un indicador especial configurado. Esta bandera activa el proceso de muestreo de entrega para utilizar el clasificador de contenido dañino para muestrear imágenes que podrían haberlo activado.
Básicamente, este algoritmo puede «impulsar» el modelo de difusión hacia generaciones más adecuadas. Esto se puede hacer tanto en el nivel de solicitud como en el nivel del clasificador de imágenes.