Desarrollar robustez y determinismo en aplicaciones LLM

Abierto AI anunciado recientemente apoyo para Resultados estructurados en su ultimo gpt-4o-2024–08–06 Los resultados estructurados en relación con los grandes modelos de lenguaje (LLM) no son nuevos: los desarrolladores han utilizado varias técnicas de ingeniería rápida o herramientas de terceros.
En este artículo, explicaremos qué son los resultados estructurados, cómo funcionan y cómo puede aplicarlos en sus propias aplicaciones basadas en LLM. Si bien el anuncio de OpenAI los hace más fáciles de implementar usando sus API (como lo demostraremos aquí), es posible que desees optar por el código abierto. Líneas principales paquete (mantenido por la encantadora gente de punto de texto), ya que se puede aplicar tanto a modelos abiertos autohospedados (por ejemplo, Mistral y LLaMA), como a API propietarias (Descargo de responsabilidad: debido a este problema Al momento de escribir este artículo, Outlines no admite la generación de JSON estructurado a través de las API de OpenAI; ¡pero eso cambiará pronto!).
Si Conjunto de datos de RedPajama Como puede verse, la gran mayoría de los datos previos al entrenamiento son textos humanos. Por lo tanto, el “lenguaje natural” es el dominio nativo de los LLM, tanto para entrada como para salida. Sin embargo, cuando creamos aplicaciones, queremos utilizar estructuras o esquemas formales legibles por máquina para encapsular nuestros datos de entrada/salida. De esta manera, integramos robustez y determinismo en nuestras aplicaciones.
Resultados estructurados Este es un mecanismo mediante el cual aplicamos un esquema predefinido en la salida del LLM. Por lo general, esto significa que estamos aplicando un esquema JSON, pero no se limita solo a JSON. En principio, podríamos aplicar XML, Markdown o un esquema completamente personalizado. Las ventajas de las salidas estructuradas son dos:
- Diseño de avisos más simple – necesitamos no ser demasiado detallado al especificar cómo se verá el resultado
- Nombres y tipos deterministas. – podemos garantizar para obtener por ejemplo un atributo
agecon unNumbertipo JSON en la respuesta de LLM
Para este ejemplo, usaremos la primera oración de Entrada de Wikipedia para Sam Altman…
Samuel Harris Altman (nacido el 22 de abril de 1985) es un empresario e inversor estadounidense mejor conocido como director ejecutivo de OpenAI desde 2019 (fue despedido brevemente y reintegrado en noviembre de 2023).
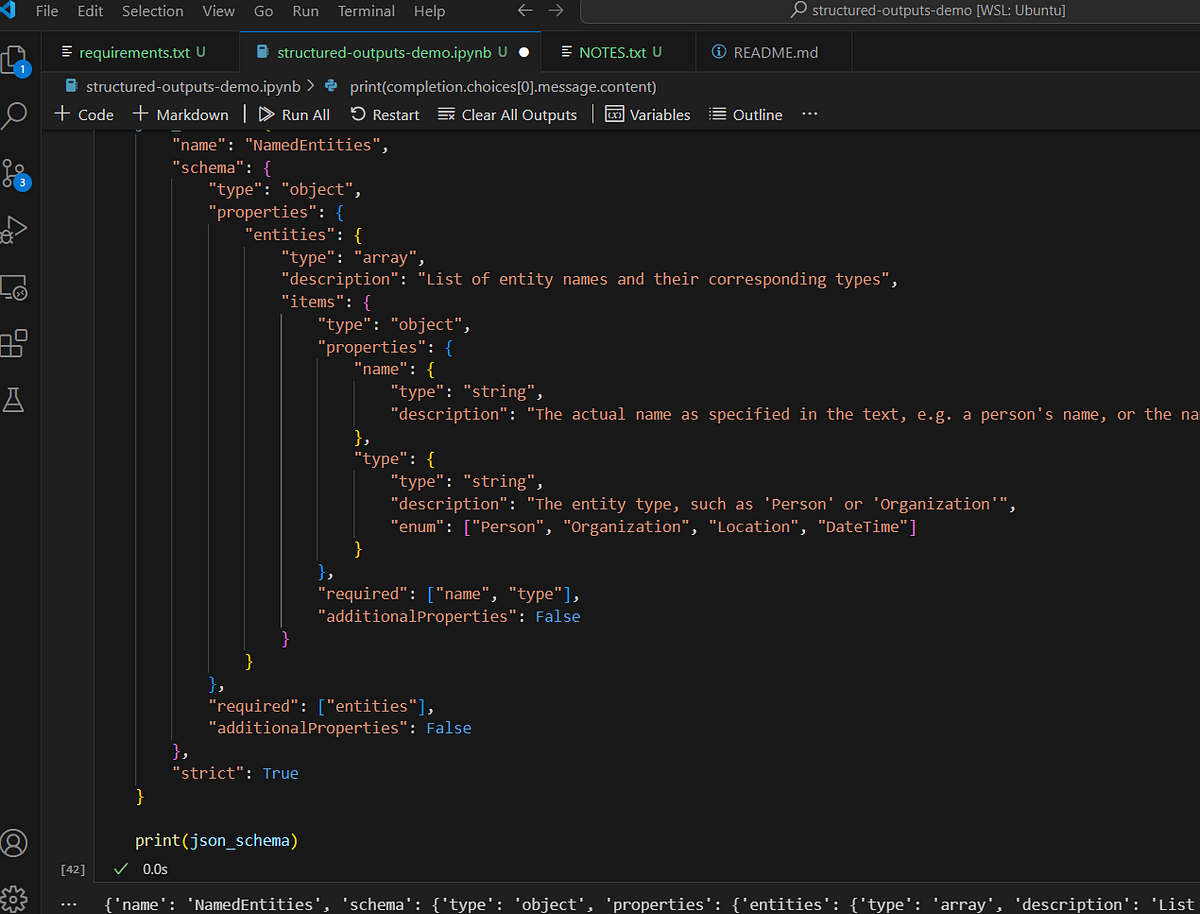
…y utilizaremos el último punto de control GPT-4o como nuestro sistema de reconocimiento de entidades nombradas (NER). Aplicaremos el siguiente esquema JSON:
json_schema = {
"name": "NamedEntities",
"schema": {
"type": "object",
"properties": {
"entities": {
"type": "array",
"description": "List of entity names and their corresponding types",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The actual name as specified in the text, e.g. a person's name, or the name of the country"
},
"type": {
"type": "string",
"description": "The entity type, such as 'Person' or 'Organization'",
"enum": ["Person", "Organization", "Location", "DateTime"]
}
},
"required": ["name", "type"],
"additionalProperties": False
}
}
},
"required": ["entities"],
"additionalProperties": False
},
"strict": True
}
Básicamente, nuestra respuesta de LLM debe contener una NamedEntities objeto, que consta de una serie de entitiescada uno contiene un name Y typeHay algunas cosas a tener en cuenta aquí. Por ejemplo, podemos imponer Enumeración tipo, que es muy útil en NER ya que podemos restringir la salida a un conjunto fijo de tipos de entidad. Necesitamos especificar todos los campos en el required tabla: sin embargo, también podemos emular campos «opcionales» configurando el tipo, por ejemplo. ["string", null] .
Ahora podemos pasar nuestro esquema, datos e instrucciones a la API. Debemos completar el response_format discusión con un dice donde nos instalamos type tiene "json_schema” y luego proporcione el diagrama correspondiente.
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": """You are a Named Entity Recognition (NER) assistant.
Your job is to identify and return all entity names and their
types for a given piece of text. You are to strictly conform
only to the following entity types: Person, Location, Organization
and DateTime. If uncertain about entity type, please ignore it.
Be careful of certain acronyms, such as role titles "CEO", "CTO",
"VP", etc - these are to be ignore.""",
},
{
"role": "user",
"content": s
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema,
}
)
El resultado debería verse así:
{ 'entities': [ {'name': 'Samuel Harris Altman', 'type': 'Person'},
{'name': 'April 22, 1985', 'type': 'DateTime'},
{'name': 'American', 'type': 'Location'},
{'name': 'OpenAI', 'type': 'Organization'},
{'name': '2019', 'type': 'DateTime'},
{'name': 'November 2023', 'type': 'DateTime'}]}
El código fuente completo utilizado en este artículo está disponible. aquí.
La magia reside en la combinación de muestreo restringidoY gramática libre de contexto (CFG). Mencionamos anteriormente que la gran mayoría de los datos previos al entrenamiento están en «lenguaje natural». Estadísticamente, esto significa que para cada paso de decodificación/muestreo, existe una probabilidad no despreciable de muestrear una muestra arbitraria del vocabulario aprendido (y en los LLM modernos, los vocabularios suelen abarcar más de 40.000 fichas). Sin embargo, cuando se trata de esquemas formales, nos gustaría eliminar rápidamente cualquier token improbable.
En el ejemplo anterior, si ya hemos generado…
{ 'entities': [ {'name': 'Samuel Harris Altman',
…así que idealmente nos gustaría colocar un sesgo logit muy alto en el 'typ token en el siguiente paso de decodificación, y una probabilidad muy baja en todos los demás tokens del vocabulario.
Esto es esencialmente lo que está sucediendo. Cuando proporcionamos el esquema, se convierte en una gramática formal, o CFG, que se utiliza para guiar los valores de sesgo logit durante la etapa de decodificación. CFG es uno de esos mecanismos informáticos y de procesamiento del lenguaje natural (PLN) de la vieja escuela que está regresando. Se presentó una muy buena introducción a CFG en esta respuesta de StackOverflowpero es esencialmente una forma de describir reglas de transformación para una colección de símbolos.
Los resultados estructurados no son algo nuevo, pero ciertamente se están convirtiendo en una prioridad con las API patentadas y los servicios LLM. Constituyen un puente entre el dominio errático e impredecible del “lenguaje natural” de los LLM y el dominio determinista y estructurado de la ingeniería de software. Los resultados estructurados son esencialmente una debe para cualquiera que diseñe aplicaciones complejas de LLM donde los resultados de LLM deben compartirse o «presentarse» en varios componentes. Aunque finalmente ha llegado el soporte de API nativa, los desarrolladores también deberían considerar el uso de bibliotecas como Outlines, ya que proporcionan una forma independiente de LLM/API para manejar resultados estructurados.