
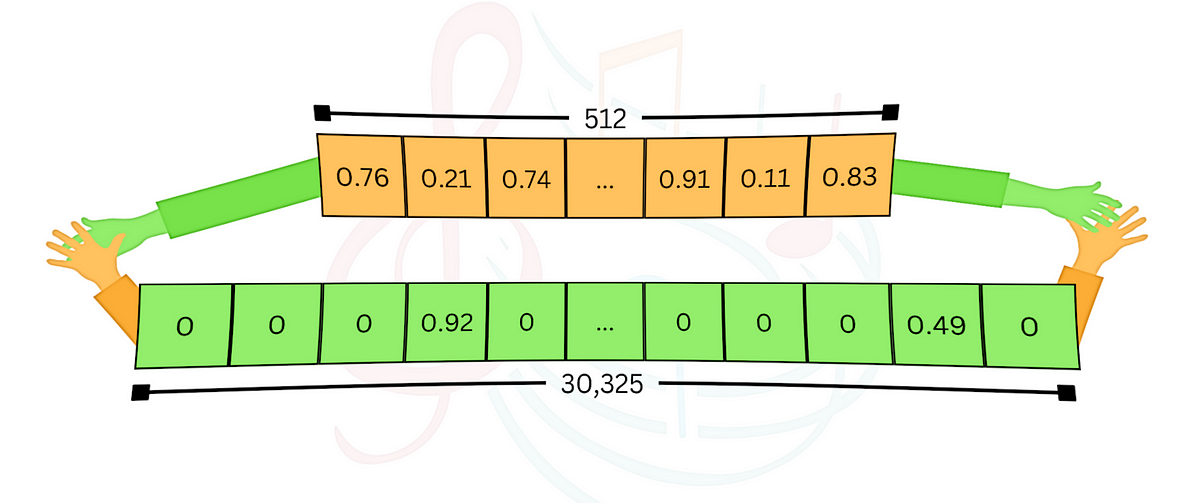

Si intercambia consultas entre los dos ejemplos anteriores y usa cada uno con la integración del otro, ambos producirán un resultado incorrecto. Esto demuestra que cada método tiene sus puntos fuertes pero también sus debilidades. La investigación híbrida combina los dos, con el objetivo de obtener lo mejor de ambos mundos. Al indexar datos con incrustaciones densas y escasas, podemos realizar búsquedas que consideren tanto la relevancia semántica como la concordancia de palabras clave, equilibrando los resultados en función de ponderaciones personalizadas. Nuevamente, la implementación interna es más complicada, pero langchain-milvus hace que su uso sea bastante sencillo. Veamos cómo funciona:
vector_store = Milvus(
embedding_function=[
sparse_embedding,
dense_embedding,
],
connection_args={"uri": "./milvus_hybrid.db"},
auto_id=True,
)
vector_store.add_texts(documents)
En esta configuración se aplican incrustaciones escasas y densas. Probemos la búsqueda híbrida de igual ponderación:
query = "Does Hot cover weather changes during weekends?"
hybrid_output = vector_store.similarity_search(
query=query,
k=1,
ranker_type="weighted",
ranker_params={"weights": [0.49, 0.51]}, # Combine both results!
)
print(f"Hybrid search results:\n{hybrid_output[0].page_content}")# output: Hybrid search results:
# In Israel, Hot is a TV provider that broadcast 7 days a week
Esto busca resultados similares utilizando cada función de integración, asigna un peso a cada puntuación y devuelve el resultado con la mejor puntuación ponderada. Podemos ver que con un poco más de peso sobre las incrustaciones densas conseguimos el resultado deseado. Esto también es válido para la segunda consulta.
Si damos más peso a las incrustaciones densas, volveremos a obtener resultados irrelevantes, como ocurre con las incrustaciones densas solas:
query = "When and where is Hot active?"
hybrid_output = vector_store.similarity_search(
query=query,
k=1,
ranker_type="weighted",
ranker_params={"weights": [0.2, 0.8]}, # Note -> the weights changed
)
print(f"Hybrid search results:\n{hybrid_output[0].page_content}")# output: Hybrid search results:
# Today was very warm during the day but cold at night
Encontrar el equilibrio adecuado entre denso y disperso no es una tarea trivial y puede considerarse como parte de un problema más amplio de optimización de hiperparámetros. Hay investigaciones y herramientas en curso que intentan abordar estos problemas en esta área, p. IBM AutoAI para RAG.
Hay muchas otras formas de adaptar y utilizar el enfoque de investigación híbrida. Por ejemplo, si cada documento tiene un título asociado, puede utilizar dos funciones de incrustación densa (posiblemente con diferentes modelos), una para el título y otra para el contenido del documento, y realizar una búsqueda híbrida en ambos índices. Milvus actualmente admite hasta 10 campos vectoriales diferentes, lo que brinda flexibilidad para aplicaciones complejas. También hay configuraciones adicionales para los métodos de indexación y reordenación. puedes ver Documentación Milvus sobre las configuraciones y opciones disponibles.



