
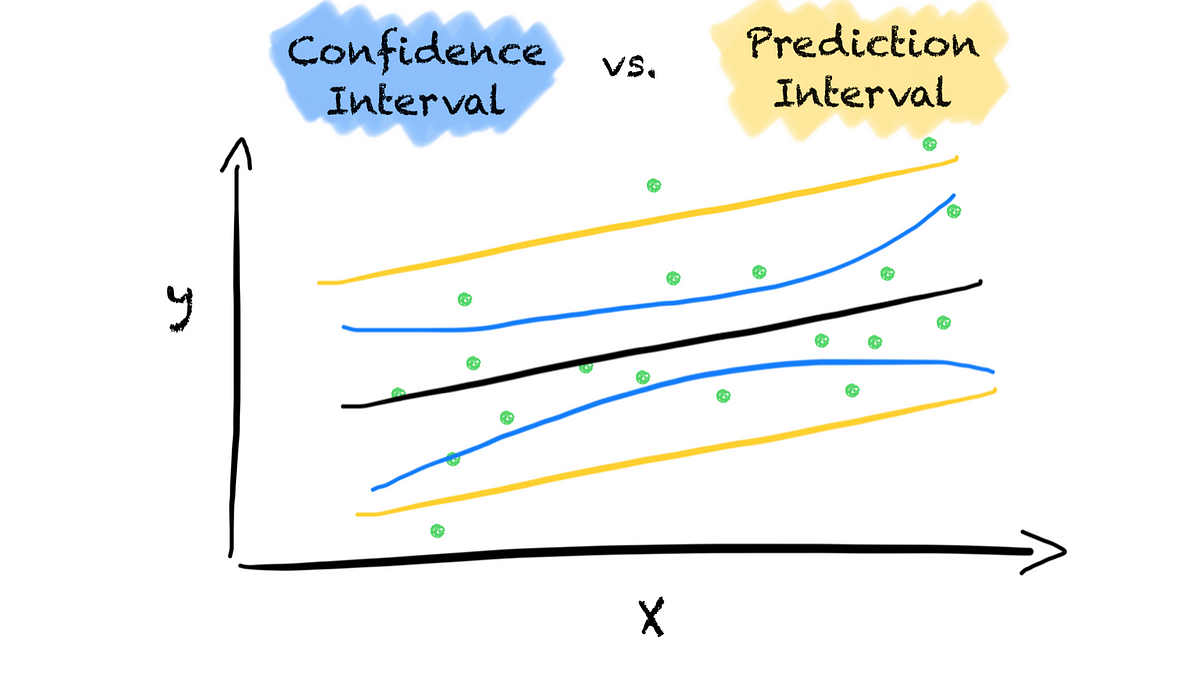
Una pequeña pero importante diferencia que debes saber

En muchas tareas de ciencia de datos, queremos saber qué tan seguros estamos del resultado. Saber cuánto podemos confiar en un resultado nos ayuda a tomar mejores decisiones.
Una vez que hayamos cuantificado el nivel de incertidumbre asociado con un resultado, podemos usarlo para:
- Planificación de escenarios para evaluar los mejores y peores escenarios.
- Evaluación de riesgos para evaluar el impacto en las decisiones.
- Evaluación de modelos para comparar diferentes modelos y su rendimiento.
- Comunicarse con los tomadores de decisiones sobre hasta qué punto deben confiar en los resultados.
¿De dónde viene la incertidumbre?
Veamos un ejemplo sencillo. Queremos estimar el precio medio de una casa de 300 metros cuadrados en Alemania. No es viable recopilar datos de todas las casas de 300 metros cuadrados. En su lugar, calcularemos el precio promedio en función de un subconjunto representativo.



