
Utilice algoritmos de clúster para manejar datos de series temporales faltantes
hace 12 horas

(Si aún no has leído la primera parte, échale un vistazo. aquí.)
La falta de datos en el análisis de series temporales es un problema recurrente.
Como exploramos en Parte 1técnicas de imputación simples o incluso Modelos basados en regresión: regresión lineal, árboles de decisión. puede llevarnos lejos.
Pero ¿y si nosotros necesidad de manejar patrones más sutilesy capturar la fina fluctuación de datos complejos de series temporales?
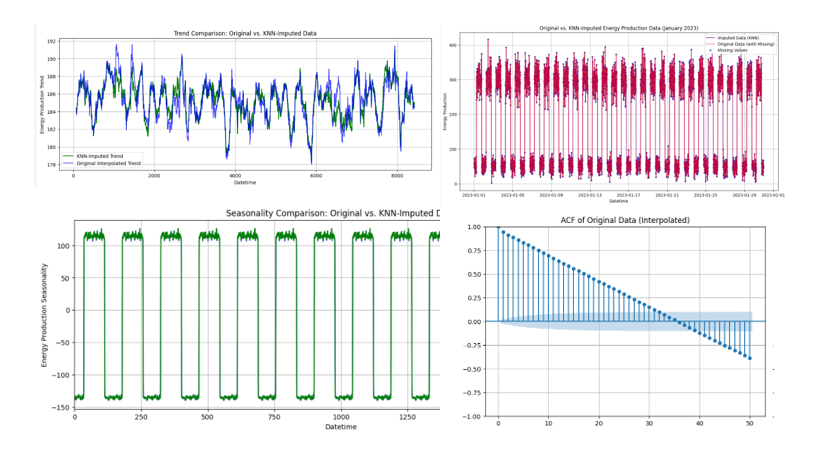
En este artículo, exploraremos K-vecinos más cercanos. Las fortalezas de este modelo incluyen pocas suposiciones sobre relaciones no lineales en sus datos; por tanto, se convierte en una solución versátil y robusta para la imputación de datos faltantes.
seremos utilizando el mismo conjunto de datos ficticios de producción de energía que ya viste en la primera parte, con un 10% de valores faltantes, introducidos aleatoriamente.
Imputaremos los datos faltantes utilizando un conjunto de datos que usted mismo puede generar fácilmente, lo que le permitirá seguir y aplicar las técnicas en tiempo real mientras explora el proceso paso a paso.



